Benchmark
Code for producing benchmark results is available here.
Here show a closed-loop benchmark for a inverted-pendulum on a cart example, sweeping the prediction and control horizons together over N = 50, 75, 100, 125. Both input and state constraints are imposed.
Specifically, similar results can be genereated with the following commands.
uv sync
uv run python run_all.py \
--problem inverted_pendulum \
--scaling \
--solvers lmpc casadi cvxpygen acados tinympc \
--horizons 50 75 100 125 \
--results-dir resultsIn this benchmark, LinearMPC.jl (denoted lmpc in the plots since its sister Python package lmpc is used) produces the fastest code across the considered horizons. Moreover, LinearMPC.jl has the smallest memory footprint. Note, however, that the dense formulation that LinearMPC.jl will sooner or later exceed that of the sparse solvers, as can been seen by the slope memory footprint.
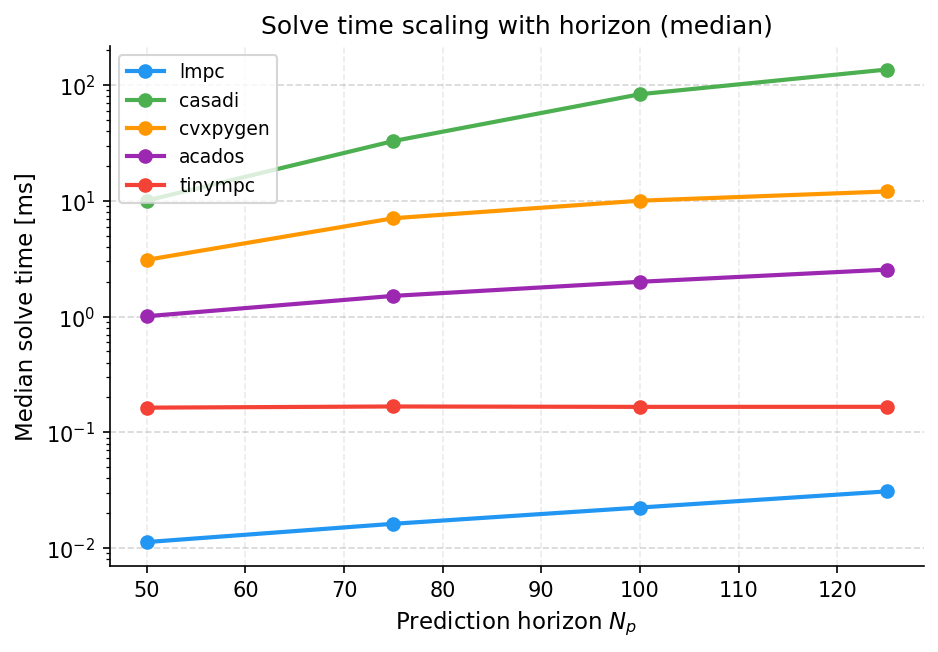
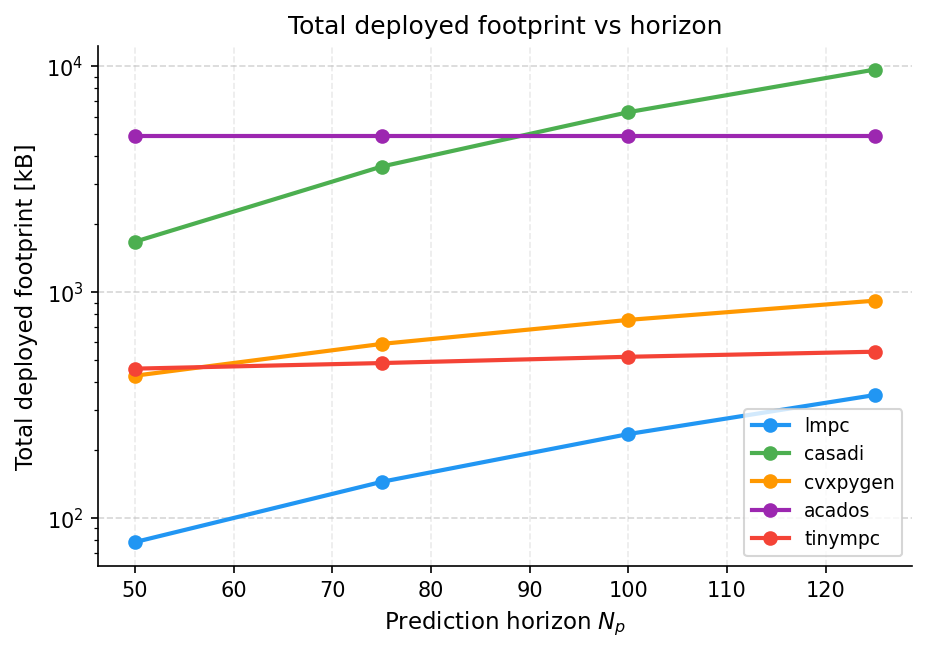
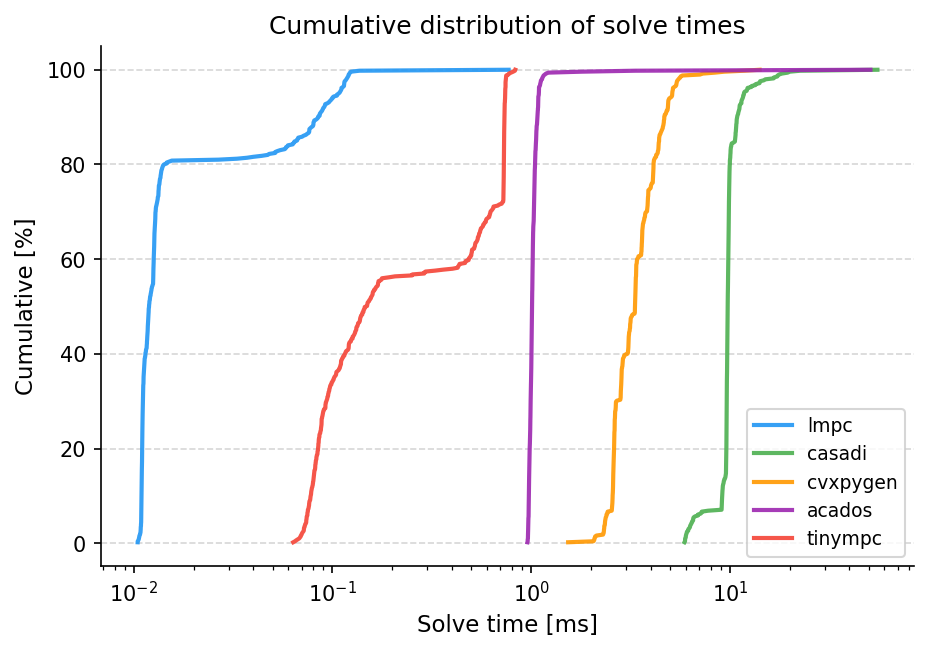
Detailed information for horizon 50:
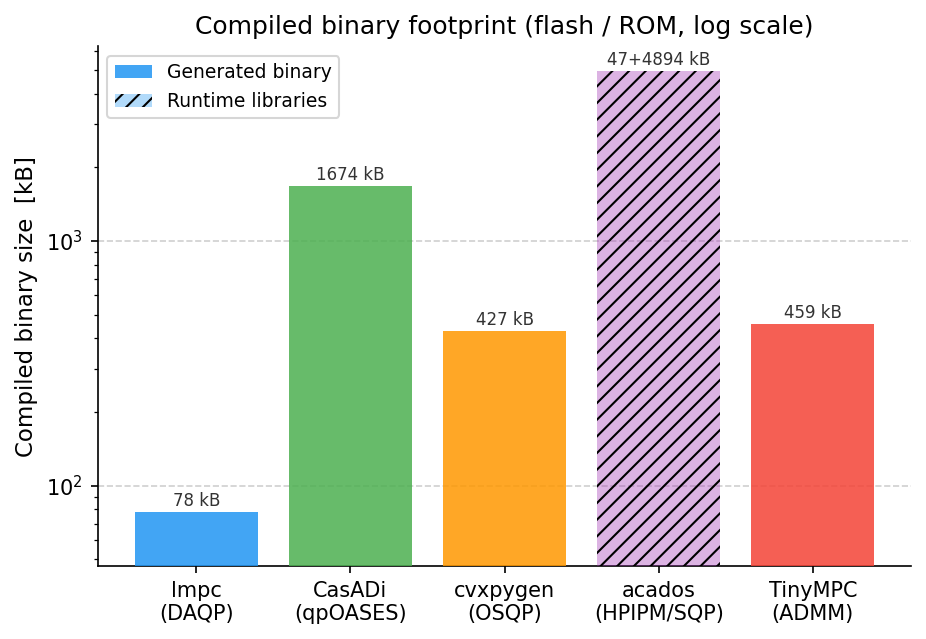
Note that the memory footprint for acados is large due to its dependence on blasfeo and hpipm. The memory footprint could be reduced if a more targeted compilation is performed.